Comparing the Actor Model and CSP Concurrency with Elixir and Clojure
18 Dec 2023Introduction
This is a digest of the talk on this topic I gave at Code BEAM STO 2022 and at ElixirConf EU 2022. I also talked about this in an episode of the Elixir Wizards podcast this month.
Before diving into this topic, I would like to first add a disclaimer that I am far from an expert on JVM and Clojure (as I have been working with Elixir most of my professional career). I gave the talk as I was intrigued by the topic and would like to share my learnings. As the saying goes, “the best way to learn a topic you’re interested in is to submit a talk proposal. If the proposal is accepted, you really have to dig into it”. I will try to present the information to the best of my knowledge, but some inaccuracies might be inevitable, in which case feel free to point them out in the comments.
In my talk, I approached the comparison from two dimensions: BEAM/ERTS vs. JVM and the Actor Model vs. CSP. Theoretically speaking, the Actor Model and CSP might be considered the two sides of the same coin. However, practically speaking, there have been some major differences in their popular implementations, with implementations of the Actor Model such as BEAM and Akka focusing a lot on the no-shared-memory aspect, while implementations of CSP such as seen in Golang, Rust and Clojure’s core.async focus a lot on the “execution flow” aspect, with the implicit underlying assumption that the concurrency still takes place in a shared-memory environment. Therefore, I considered it helpful to also touch upon the differences between the BEAM and the JVM, which serves as a nice foundation for understanding the differences between the implementations.
BEAM vs. JVM
BEAM
Here I would like to emphasize these two aspects of the BEAM VM: per-process memory space and preemptive scheduling.
Per-process memory
The following is a simplified illustration of the BEAM/ERTS memory layout (Pool 2015). The key takeaway here is that each process has its separate heap, i.e. they share no memory with each other, which is key to its Actor Model, which we’ll discuss later.
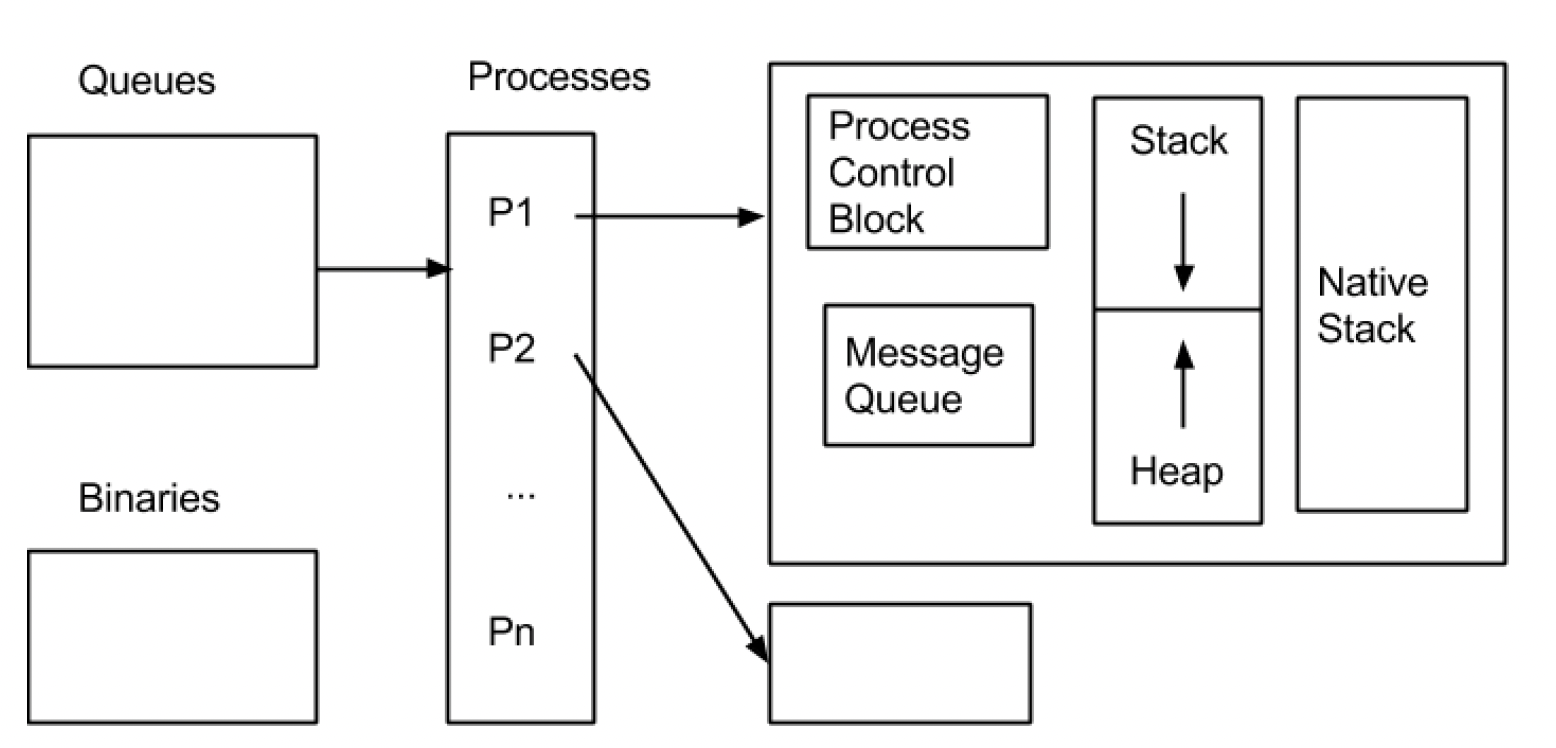
A corollary of this is that there will be no global garbage collection that could potentially impact all processes at the same time.
(There are some optimizations, such as large binaries being stored separately, so that only pointers to them instead of full copies of them need to be passed around, which we will not explore in detail here.)
Preemptive scheduling
The mechanism with which schedulers work is a unique and sometimes overlooked feature of BEAM. This is what enables the soft real-time nature of BEAM and what makes it great at handling massive concurrency challenges (but maybe not the best at handling CPU-intensive tasks).
When you launch an iex session, the smp:20:20 part actually indicates the number of schedulers available (“smp” stands for “Symmetrical Multiple Processes”). It’s usually the same as the number of CPU cores.
Since OTP 13, each scheduler has its own process queue. All processes of the BEAM are load-balanced across all schedulers.
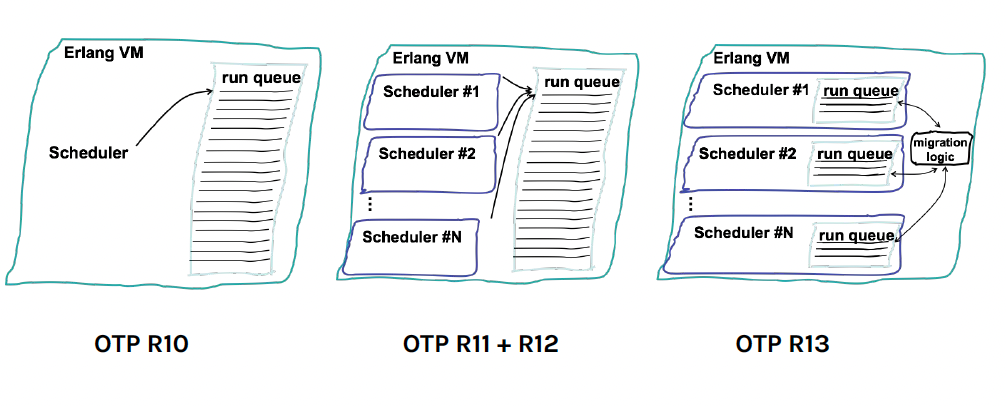
With preemptive scheduling, once a process runs for 4000 reductions (one reduction is approximately 1 function call), it will be put to the back of the queue, and replaced by the next process in the queue. This ensures highly consistent time-sharing across all processes. (Independent GC also helps.) Imagine if you have 100K connections being handled on the same VM via 100K processes, nobody will necessarily hog any more CPU time share than any other process, and everybody gets the same experience, which is great.
However, you can easily see how this might not be ideal if you need to handle a special number-crunching workload which requires intensive CPU usage over a sustained period of time (dynamic typing is another negative against this use case). Indeed, you would then usually resort to NIFs, i.e. Native Implemented Functions (which are run on dirty schedulers), or ports (a mechanism with which BEAM can communicate with external programs). Note that NIFs are not subject to preemptive scheduling however (thus “dirty”), and thus can actually block if you’re not careful on how it terminates.
JVM
In contrast to BEAM’s per-process memory model and preemptive scheduling, JVM takes a relatively conventional approach which many might be more familiar with.
Shared Heap
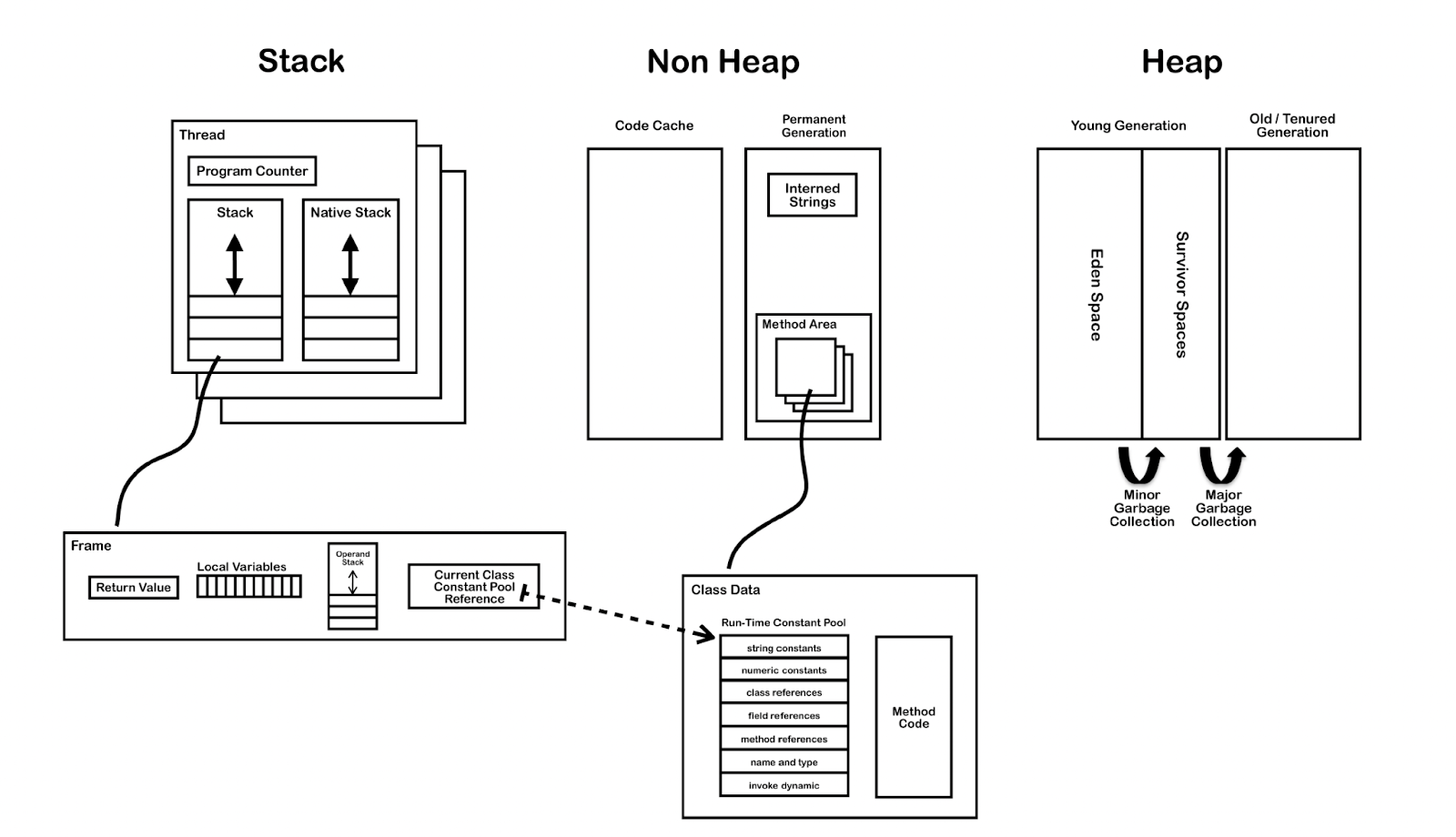
JVM has a heap which is shared by all threads, which facilitates shared-state concurrency, in which multiple threads can potentially read and write the same memory space and thus the same resource. This requires the use of concurrency mechanisms such as locks in Java or atom, agent, ref, var in Clojure to avoid race conditions, which however could result in deadlocks if not careful. At the same time, it does make some scenarios which require coordination between multiple threads to perform heavylifting during a CPU-intensive task easier.
(Theoretically, a stop-the-world garbage collection operation can also result in all threads being affected and halted at the same time in contrast to the independent processes run on the BEAM VM, though from what I understand, a lot of optimizations have been made on this front, so this is generally not such a big issue in recent versions of JVMs anymore.)
OS threads and OS scheduler
Conventionally, the JVM creates operating system threads and relies on the operating system scheduler to run the threads. Therefore, JVM threads are much heavier than BEAM’s lightweight processes, and the frequent blocking and unblocking of threads in IO-intensive tasks will be costly. On the other hand, they’re a great fit for CPU-intensive tasks.
(Note: With the formal introduction of Project Loom in JVM 23, Java has also made virtual threads available, which are much more lightweight and in a sense share similarities with BEAM processes. As it’s still in its early days, its impact on libraries such as Akka and core.async remains to be seen.)
The Actor Model vs. CSP
The Actor Model (Hewitt 1973) and Communicating Sequential Processes (Hoare 1978) were proposed close to each other and co-evolved over the years. (Anecdotally, the creators of Erlang independently arrived at an idea similar to what Hewitt proposed, without first having known about it.)
Theoretically, you can think of the main difference between those two as the distinction between processes as the first-class entities vs. channels as the first-class entities. Beyond that though, the real-world implementations of the Actor Model (e.g. BEAM, Akka) and CSP (e.g. Go, Rust, Clojure’s core.async) tend to also have different practical foci, which we’ll explore in more detail up next.
The Actor Model on the BEAM
As we have seen in the previous section on the BEAM, one key feature of the Actor Model is how the processes should share no memory with one another.
This goes hand-in-hand with the fact that processes are first-class: each process has a unique name; processes communicate by identifying each other by name, then sending messages directly to each other. This concurrency model directly eliminates a lot of race conditions which can lead to subtle bugs in a shared-memory language. Theoretically, all you need to trace are the messages sent and the behaviors of each process upon receiving certain messages. (Of course, as anybody who has worked with Erlang/Elixir can attest, the reality of debugging can still be much messier than what’s promised here, which is unavoidable.)
A related property for actors is that send is non-blocking by default, while receive is blocking. What this means is that a sender process can in a sense “fire and forget” every message it sends, while it’s up to the receiver process to handle messages that arrive at its mailbox via entering a receive call, which would block the process from further operations until a message matching one of the clauses specified in the receive block arrives. Here’s an example in iex:
iex(1)> iex_process = self()
#PID<0.113.0>
iex(2)> spawn(fn -> send(iex_process, {:hello, self()}) end)
#PID<0.114.0>
iex(3)> receive do
...(3)> {:hello, pid} -> "Got hello from #{inspect pid}"
...(3)> end
"Got hello from #PID<0.114.0>"
iex(4)> 1 + 1 # Now iex_process is unblocked and able to do something else
2
Note that if none of the receive block’s clauses match the incoming message, the process will keep waiting and thus be blocked:
iex(1)> iex_process = self()
#PID<0.113.0>
iex(2)> spawn(fn -> send(iex_process, {:hello, self()}) end)
#PID<0.114.0>
iex(3)> receive do
...(3)> :unmatched -> "Will not match here"
...(3)> end
At this point iex is blocked and you can’t do anything further except for e.g. interrupting it.
In addition, a process can never “refuse” to receive messages, and a mailbox’s size is theoretically unlimited if the messages arrive but remain unhandled. In fact, one way to crash a BEAM VM is to overflow the mailboxes! Here’s an illustration of this behavior:
iex(1)> iex_process = self()
#PID<0.113.0>
iex(2)> :erlang.process_info(iex_process, :messages) # Empty mailbox at this point
{:messages, []}
iex(3)> spawn(fn -> send(iex_process, {:hello, self()}) end)
#PID<0.114.0>
iex(4)> :erlang.process_info(iex_process, :messages) # The message is already in the mailbox
{:messages, [hello: #PID<0.114.0>]}
Note how the message is already in the mailbox even though the iex process didn’t specify any receive block to handle incoming messages at all, and may simply be going on with its business obliviously.
(Of course, we rarely need to spawn raw processes and write receive blocks directly in production Erlang/Elixir code. This is because OTP already offers a whole package of abstractions to make the life of developers much easier. A well-known abstraction is gen_server which for example lets you specify with a clear syntax callback functions (handle_call, handle_cast, handle_info) which spell out how the process should respond to incoming messages, and handles a lot of edge cases under the hood so that you don’t need to bother handrolling a receive block. OTP also offers many other tools such as process linking & supervision, node clustering, tracers and debuggers, which are out of discussion scope here.)
CSP with core.async in Clojure
Aside: Conventional approaches to concurrency in Clojure
Before beginning this section, I would first like to point out that core.async is a later addition to Clojure, while Clojure’s more conventional approach to concurrency involves tools such as ref, atom, agent, and var, which, similar to locks in Java, facilitate shared-memory concurrency, but can be much more ergonomic and pleasant to use due to Clojure’s functional nature, which enables the separation of identity and state via the widespread use of persistent data structures (“persistent” in this context refers to the fact that the data structure always preserves its previous version when modified. A classic example of this is a list, to which if you prepend a new head, the tail remains unchanged and a reference to which can be easily kept around as the previous version of the entire list. This is of course a feature shared by other functional languages such as Elixir). Another interesting concept is Software Transactional Memory (STM), which allows you to keep a series of reads and writes in one single transaction, somewhat similar to a database transaction. These ideas are not unique to Clojure: Various functional languages such as Haskell offer similar tools for shared-memory concurrency.
When recording the podcast, Owen raised a very good point that when he first started with Elixir, he thought the no-shared-memory nature of the Actor Model and the BEAM is something that automatically comes with functional programming, which turned out to not be the case. In fact most functional programming languages still handle shared-memory concurrency, just with a different (and some may argue more elegant) flavor compared to how procedural languages traditionally do it. We won’t have time to go into the details of these, though I’d encourage you to refer to the resources listed in at the end of the post if you’re interested in knowing more.
core.async and CSP
Different from the Actor Model, in CSP, processes are anonymous, while channels are named first-class entities. In Clojure’s core.async, you can return a channel from a function and pass it around. Readers and writers use channels to relay messages.
In core.async, the default channel is blocking and synchronous: Once a writer writes a message into the channel, it will be blocked until a reader reads the message.
(let [c (chan)]
(thread (>!! c "hello") (println "writer unblocked"))
(thread (println (<!! c))))
Output:
hello
writer unblocked
In this example, we create a channel named c and then spawn two JVM threads. The first thread writes "hello" into the channel, while the second thread reads the message off the channel and prints it immediately, after which the writer gets unblocked.
Similarly, once a reader decides to listen on a channel, it will be blocked until a writer delivers a message:
(let [c (chan)]
(thread (println (<!! c)) (println "reader unblocked"))
(thread (>!! c "hello")))
Here, the reader is blocked first, before it later gets unblocked once the writer puts a message "hello" into the channel.
(There are variants such as buffered channels, which enable non-blocking behavior to some extent: As long as the buffer is not full, a writer will be able to fire and forget and will not be blocked, similar to how a BEAM process sends its message. However, unlike the unlimited mailboxes in BEAM/OTP, there are no channels of unlimited size in core.async, meaning even a buffered channel will get full at some point. Sliding channels and dropping channels can also be used, which drops the oldest or the newest message when full.)
Unlike BEAM mailboxes, channels can be explicitly closed to further writes, after which remaining messages can still be read from the channel.
(let [c (chan)]
(thread (>!! c "hello"))
(close! c)
(thread (println (<!! c))))
In terms of topology, each channel can potentially have zero to many readers and writers, and each thread can decide to write to and read from multiple channels at the same time:
- When there are multiple readers for one channel, a message will only be read once by at most one reader.
- When there are multiple writers for one channel, all other writers will be blocked after the channel is full.
- You can use
alts!!incore.async(in Go:select) to let a reader read from multiple channels. It will select the channel that first receives a message. Here’s an example from the official guide:
(let [c1 (chan)
c2 (chan)]
(thread (while true
(let [[v ch] (alts!! [c1 c2])]
(println "Read" v "from" ch))))
(>!! c1 "hi")
(>!! c2 "there"))
Output:
Read hi from #object[clojure.core.async.impl.channels.ManyToManyChannel 0x5cd1c0c4 clojure.core.async.impl.channels.ManyToManyChannel@5cd1c0c4]
Read there from #object[clojure.core.async.impl.channels.ManyToManyChannel 0xd59d3dd clojure.core.async.impl.channels.ManyToManyChannel@d59d3dd]
“go blocks” in core.async
There are actually two ways to run a CSP process for core.async: An actual JVM thread, which is initialized with thread as seen in the examples above, and an inversion of control “thread” initialized with the go macro.
Recall from the JVM discussion that blocking/unblocking each JVM thread is heavy, unlike the lightweight processes that live on the BEAM. In the case of the go blocks, a fixed-size thread pool is used under the hood. Some macro magic takes place to “park” and “unpark” the blocks and switch them in and out of the threads in the pool, instead of the thread variant where a real JVM thread will be blocked. This makes go blocks much more lightweight. Here’s an example taken from the core.async repo:
(let [n 1000
cs (repeatedly n chan)
begin (System/currentTimeMillis)]
(doseq [c cs] (go (>! c "hi")))
(dotimes [i n]
(let [[v c] (alts!! cs)]
(assert (= "hi" v))))
(println n "msgs in" (- (System/currentTimeMillis) begin) "ms"))
which output “1000 msgs in 194 ms”, i.e. we spawned 1000 channels and were able to read and write to each of them in mere 194ms!
Inversion of control with go blocks
Another interesting thing to note, as mentioned earlier, is how the use of CSP in Go, Clojure, Rust etc. still facilitates working with shared memory, unlike the Actor Model used on the BEAM and even in Akka to some extent:
“It should be noted that Clojure’s mechanisms for concurrent use of state remain viable, and channels are oriented towards the flow aspects of a system.” - Rich Hickey
“Messages should be immutable, this is to avoid the shared mutable state trap.” - Akka
This “flow aspects” mentioned by Rich Hickey is emphasized by the fact that not only can go blocks be more efficient than thread blocks on the JVM, they also serve as an inversion of control mechanism. This is particularly evident in its use with ClojureScript, which due to its runtime is singlethreaded by nature. The parking and unparking of go processes onto a single thread greatly simplifies the conventional challenge of callback hell. Consider the following example (adapted from Seven Concurrency Models in Seven Weeks):
(defn show [elem]
(set! (.. elem -style -display) "block"))
(defn hide [elem]
(set! (.. elem -style -display) "none"))
(defn start [])
(go
(let [page1 (dom/getElement "page1")
page2 (dom/getElement "page2")
next-page-button (dom/getElement "next")
next-page (get-events next-page-button "click")]
(show page1)
(<! next-page) ;; Waiting for the user to click on the next-page-button and trigger the event.
(hide page1)
(show page2))))
(set! (.-onload js/window) start)
If you are familiar with ES6’s async/await, you may immediately see the parallels between the use of <! here and the await keyword. Back in the days, fewer languages had this “async” inversion of control construct. (async/await was only formally added to JavaScript in 2017.) Nowadays it’s very much widespread as it offers tangible benefits, as I’m sure everybody who has refactored some JS callback hell with async/await can attest to.
Conclusion
For many developers, concurrency concepts might sound like something rather removed from their day-to-day work. However, an understanding of the concurrency properties of various programming languages and common concurrency patterns can be an integral part of your general knowledge. I just talked to a developer who was tasked with building a system completely in NodeJS, but decided and convinced the team that it might be a better idea to build the payment processing component in Elixir, which is still working extremely well under heavy traffic a few years later. On the other hand, I also remember a blog post from Discord a few years ago on how they needed to delegate some CPU-intensive tasks to Rust in their server codebase mainly based on Elixir, which as mentioned earlier might not be a one-size-fit-all language especially when you’re faced with the need to handle heavy, sustained workloads.
Having a thorough understanding of the concurrency model of the language you work with daily also helps you have a much firmer grasp on your programs’ behaviors.
This topic is so big that it’s impossible to cover it with a talk, a podcast episode, or a blog post. If you’re interested in exploring further, I would highly recommend the book Seven Concurrency Models in Seven Weeks, which I greatly enjoyed, and the other resources listed below. Even if you won’t get to try out all the concurrency patterns and programming languages at work, this knowledge is intellectually very satisfying in its own right, and can aid you greatly in your journey to becoming a better programmer.
References and Further Resources
- Seven Concurrency Models in Seven Weeks
- Elixir in Action
- Designing for Scalability with Erlang/OTP
- The Joy of Clojure
- Actor Model of Computation (Hewitt 1973)
- Communicating Sequential Processes (Hoare 1978)
- Comparison of Erlang Runtime System and Java Virtual Machine (Pool 2015)
- Hewitt, Meijer and Szyperski: The Actor Model (Video discussion)
- Clojure Concurrency - Rich Hickey’s 2008 Talk
- Clojure core.async Channels - announcement in 2013
- Clojure core.async - Rich Hickey’s 2013 Talk
- JEP 425: Virtual Threads (Preview)